DeepSpeech & CommonVoice
Tilman Kamp, FOSDEM 2018
tilmankamp.github.io/FOSDEM2018
What are we doing?
https://github.com/mozilla/DeepSpeech
DeepSpeech is a speech to text (STT) system
based on machine learning
(using the TensorFlow machine learning framework)
Why are we doing this?
Reason 1
State of the art alternative to proprietary solutions
»I am sorry, Dave...«
Reason 2
Offline support
privacy + low latency
Reason 3
End-to-end machine learning approach
scaling + quality
User's perspective (embedding)
»Your power is sufficient, I said.«
from deepspeech.model import Model
# ...
def main():
# ...
ds = Model(args.model, ..., args.alphabet, ...)
ds.enableDecoderWithLM(args.alphabet, args.lm, args.trie, ...)
rate, audio = wav.read(args.audio)
transcript = ds.stt(audio, rate)
print(transcript)
if __name__ == '__main__':
main()var audioStream = new MemoryStream()
Fs.createReadStream(process.argv[3]).
pipe(Sox({ output: { bits: 16, rate: 16000, channels: 1, type: 'raw' } })).
pipe(audioStream)
audioStream.on('finish', () => {
audioBuffer = audioStream.toBuffer()
var model = new Ds.Model(process.argv[2], ..., process.argv[4])
if (process.argv.length > 6) {
model.enableDecoderWithLM(process.argv[4], process.argv[5], process.argv[6], ...)
}
// LocalDsSTT() expected a short*
console.log(model.stt(audioBuffer.slice(0, audioBuffer.length / 2), 16000))
})BTW
Our community also provided Rust and Go bindings!
Performance
| Human WER | DeepSpeech WER |
|---|---|
| 5.83% | 5.6% |
Set: librivox clean test
Training and development
Getting data
https://voice.mozilla.org/data
https://voice.mozilla.org
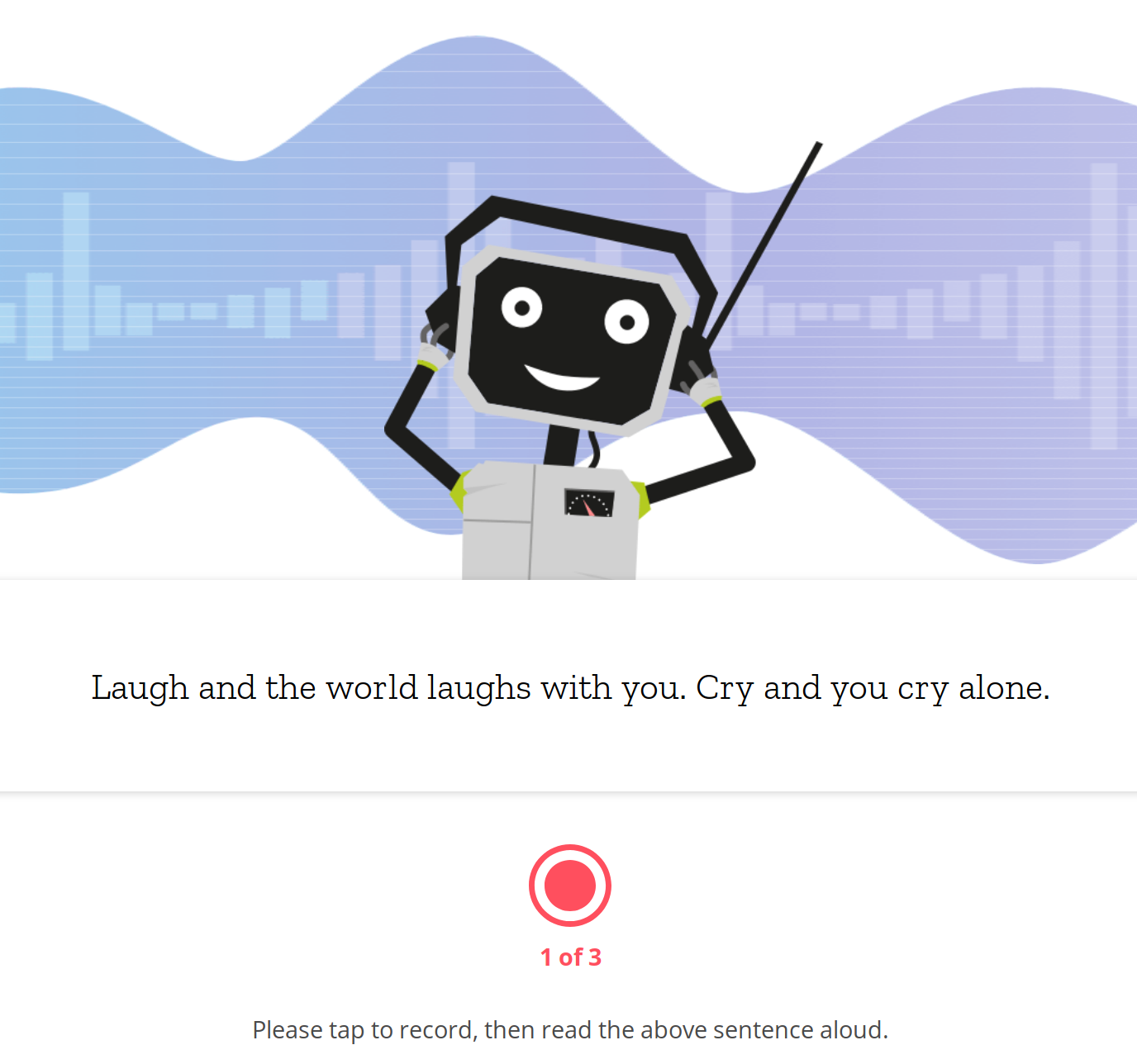
Contributing voice samples
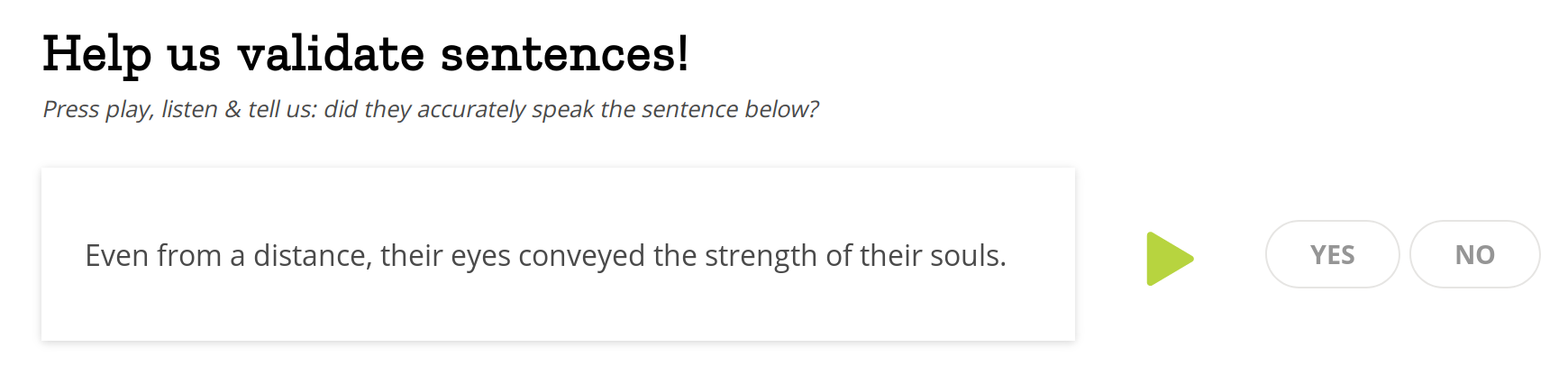
Validating voice samples
Micro tutorial
Training a new language from scratch
<terminology>
loss
how different the actual outcome is from the expected outcome
sets in a data corpus
| train-set | the data the model is trained with |
| dev-set | not trained, but used for validation |
| test-set | unbiased test at the end of the training |
epoch
the whole train-set got applied to the model one time

overfitting
actually we need two models
| model | job |
|---|---|
| acoustic | listens and identifies letters |
| language | reads and understands orthography |
</terminology>
so let's begin...
»Typograf Jakob zürnt schweißgequält vom öden Text.«
#!/usr/bin/env bash
python -u DeepSpeech.py \
--train_files "/home/demo/miniger/miniger-train.csv" \
--dev_files "/home/demo/miniger/miniger-train.csv" \
--test_files "/home/demo/miniger/miniger-train.csv" \
--alphabet_config_path "/home/demo/german-models/alphabet.txt" \
--lm_binary_path "/home/demo/german-models/lm.binary" \
--lm_trie_path "/home/demo/german-models/trie" \
--learning_rate 0.000025 \
--dropout_rate 0 \
--word_count_weight 3.5 \
--log_level 1 \
--display_step 1 \
--epoch 200 \
--export_dir "/home/demo/german-models"Next steps
Get more transcribed voice data
Get more and contemporary language model texts
Tune your hyper parameters
Get hardware - ML is computing-intensive as hell
Spread the word
Roadmap 2018
Another language
Streaming support
Optimizing for noisy backgrounds
(Thanks to freesound.org)
Text To Speech (TTS)
Talk to us
https://discourse.mozilla.org/c/deep-speech
https://wiki.mozilla.org/IRC - #machinelearning